

Whitepaper: Introducing SCA 2.0: Prioritize Risk, Reduce False Positives, and Eliminate SCA Alert Fatigue
Download Today! >Share:



When a developer wants to know what an application they’ve developed is doing, there are a number of different techniques that can be used.

But before I dive into the different options, why would a developer even be asking this question in the first place?
Let’s start with customer conversations—sometimes we pose the question: “Do you know what your application is doing, and would you stake your job on it?”
Let’s face it. As soon as you import one library or build/runtime dependency, the ability to answer that question definitively really becomes tough. You may know what your code is doing, but can you say the same about the libraries you import? What about the libraries imported by the libraries you import (and so on)?
Oftentimes the question, “What is my application doing?”, is posed by a developer when trying to answer a totally different question: “Is my application doing what it should be doing (eg, what I coded it to do)?” It should be obvious that to answer the latter question, you need to answer the former.
So, if I’m a developer and I’m being asked to stake my job on the correct behavior of my application, how do I know what my application is really doing?
To completely answer this question in a foolproof and provable way, you’d need a trace of every instruction the application executed. Clearly, that would be too much information to process (consider a modern processor that executes billions of instructions per second). As a developer, could you decipher the sequence below? Your application is executing these instructions; is it “doing the right thing?”
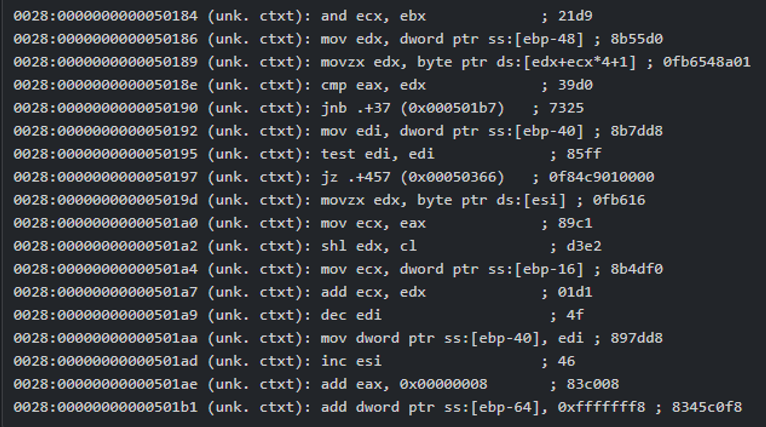
… continues for billions of instructions …
Of course, this is an extreme example of “observability”—observing every instruction an application executes—which is clearly going to overwhelm anyone. However, in theory, all application behavior can be deduced from these first principles. But we don’t observe applications this way because the amount of noise is overwhelming. A modern CPU could execute several billion instructions in a second and we’d quickly lose context trying to understand what is going on.
Let’s elevate our observability location from individual instructions to individual system calls. This is what ptrace/strace/ktrace and eBPF solutions will provide: a list of every system call the application makes. Would you (a skilled developer) be able to know if your application is “doing the right thing” using the following?
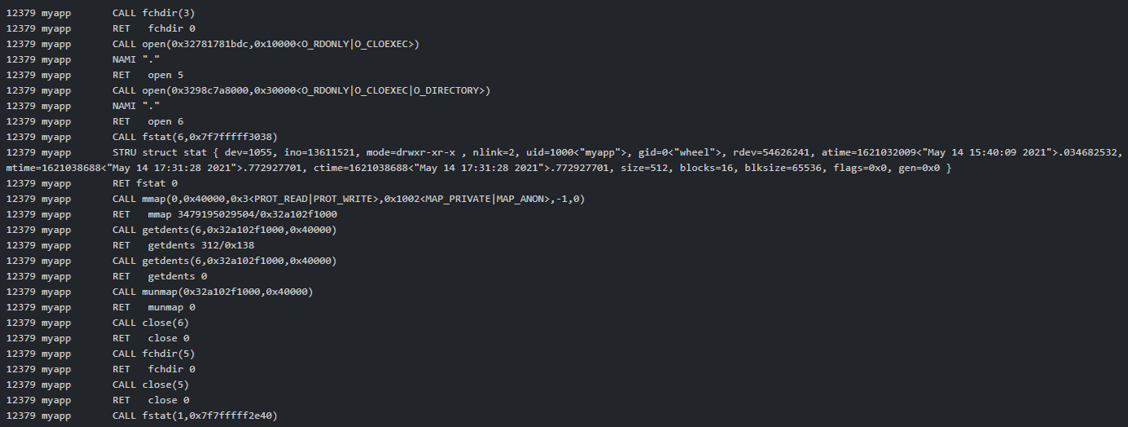
This is better than the first example – instead of individual instructions, we are now able to discern at a very low level what the application is doing. But clearly, this is still tough for an average developer to make sense of; we are still “losing sight of the forest for the trees.”
Granted, typical observability products that observe system call dispatching are not going to show the developer the raw output as I’ve shown above. They will generally attempt to make the output at least somewhat more readable.
If I provided any of you with the output above, would you stake your job on being able to say, “Yes, based on that information, my application is doing the right thing.”? I wouldn’t because the information is still too low level.

What if I presented you with the following information:

Clearly, the output above has more semantic meaning. A developer could easily see they somehow allowed a bogus logon and allowed that user to delete data they shouldn’t have had access to.
If you had to stake your job on it, which types of observations would you prefer? The billion or so individual instructions, the million or so system calls, or the higher-level insights shown in the last example?
</rhetorical question>
I’m a firm believer that the more relevant and contextually meaningful data you provide to a developer, the faster they will be able to understand the original question posed here: “Is your application doing the right thing?”
At Deepfactor, we’re all developers. We understand what developers need and we understand that developers are not always security gurus or experts. Our goal is to highlight possible issues at runtime that may be in your code (where “your code” includes anything you might import) before issues make it to production.
If you’re curious to know more, request a demo here or give us a try observing your own applications.
Next time, I’ll dig deeper into one of our observations (we have over 175) and show how you (a developer) can stop potential exploits before your code reaches production.
Stay tuned!
Deepfactor is the industry’s first Continuous Observability platform enabling Engineering and AppSec teams to find and triage RUNTIME security, privacy, and compliance risks in your applications—including 3rd party components—within the DevOps pipeline.  With zero code changes, Deepfactor automatically observes billions of live telemetry events in every thread/process/container to detect anomalies during test, staging, and production. Deep Insights cover system call risks, data risks, behavior risks, DAST scans, a software bill of materials (SBOM), and vulnerable dependencies to create high-fidelity alerts with actionable evidence. Reduce MTTR, accelerate release velocity, and ‘start left’ to create and maintain secure and compliant apps. Check out our runtime AppSec observability webinars on-demand and learn more about Deepfactor today.
With zero code changes, Deepfactor automatically observes billions of live telemetry events in every thread/process/container to detect anomalies during test, staging, and production. Deep Insights cover system call risks, data risks, behavior risks, DAST scans, a software bill of materials (SBOM), and vulnerable dependencies to create high-fidelity alerts with actionable evidence. Reduce MTTR, accelerate release velocity, and ‘start left’ to create and maintain secure and compliant apps. Check out our runtime AppSec observability webinars on-demand and learn more about Deepfactor today.