

Whitepaper: Introducing SCA 2.0: Prioritize Risk, Reduce False Positives, and Eliminate SCA Alert Fatigue
Download Today! >Share:



Have you ever contemplated why some teams, whether they are sports teams or business teams or any kind of team, move from good to great? Is it luck or conscious effort? According to Jim Collins, author of Good to Great: Why Some Companies Make the Leap and Others Don’t, “Greatness is not a function of circumstance. Greatness, it turns out, is largely a matter of conscious choice, and discipline.”
 So, in our software development world, what makes engineering teams good vs. great? Let’s look at our CI/CD pipeline:
So, in our software development world, what makes engineering teams good vs. great? Let’s look at our CI/CD pipeline:
- When you need to build fast, you use Continuous Integration
- When you need to deploy fast, you use Continuous Delivery
- When you need to detect functionality bugs fast, you use Continuous Testing
All GOOD engineering teams cover these three. But to be a GREAT engineering team, you can’t only go fast…you must go fast with confidence. Where does this confidence come from? Typically, by knowing that your team hasn’t inadvertently (or maliciously) introduced unwanted modules into your product, or introduced security issues, compliance issues or performance bottlenecks into your application. We call this ability to continuously detect security, compliance & performance risks in your application automatically for every release – ‘Continuous Observability’. When you need to detect security, compliance, and performance risks fast, you need to use Continuous Observability—that “greatness factor”—which delivers the confidence needed for both engineering teams and AppSec teams to move from good to great, together.
When we talk about Continuous Observability, we mean technology that observes ACTUAL live application behavior at RUNTIME to detect anomalies and prioritize alerts. But why emphasize RUNTIME observability? Let me use a common example to explain. When you go to buy a car, do you make the decision solely based on how it looks parked at the dealership? Of course not. Looking at a parked car is different from test-driving it. And you certainly don’t want to accidentally buy a lemon! You need to look at the car while it’s parked AND see how it handles during a test drive. Similarly, static (parked) code analysis is different from observing a running application. Hence, the importance of Runtime, or Continuous, Observability.
Is Observability the next frontier of innovation in DevSecOps? Let’s examine the CI/CD pipeline and discuss where Continuous Observability fits. We see monitoring tools designed for operators to secure the infrastructure and that provide production-related visibility. For example, StackRox and Aqua provide Container/Kubernetes/Docker security; Tenable and Qualys scan for what’s on your host; companies such as DataDog or AppDynamics or New Relic provide performance and security visibility. These tools are great because they give the Site Reliability Engineers and the Ops teams visibility into what’s happening in the infrastructure on which you’re deploying your application.
When it comes to the Dev teams, however, you need a different category of insights. You need to know what’s happening inside your application and where in the code it’s happening. The static piece is provided by a combination of SAST and SCA and container image scanning tools. But for today’s modern app, the runtime piece is missing1, and that’s where Continuous Observability fills the gap. And that’s exactly what DeepFactor provides. Think of it like this: similar to how DataDog or AppDynamics or New Relic provide performance and security visibility to OPERATORS so they can ‘secure the infra’, DeepFactor provides visibility to DEVELOPERs so they can ‘secure the source’—the applications and the 3rd parties that your engineers use as part of your app.
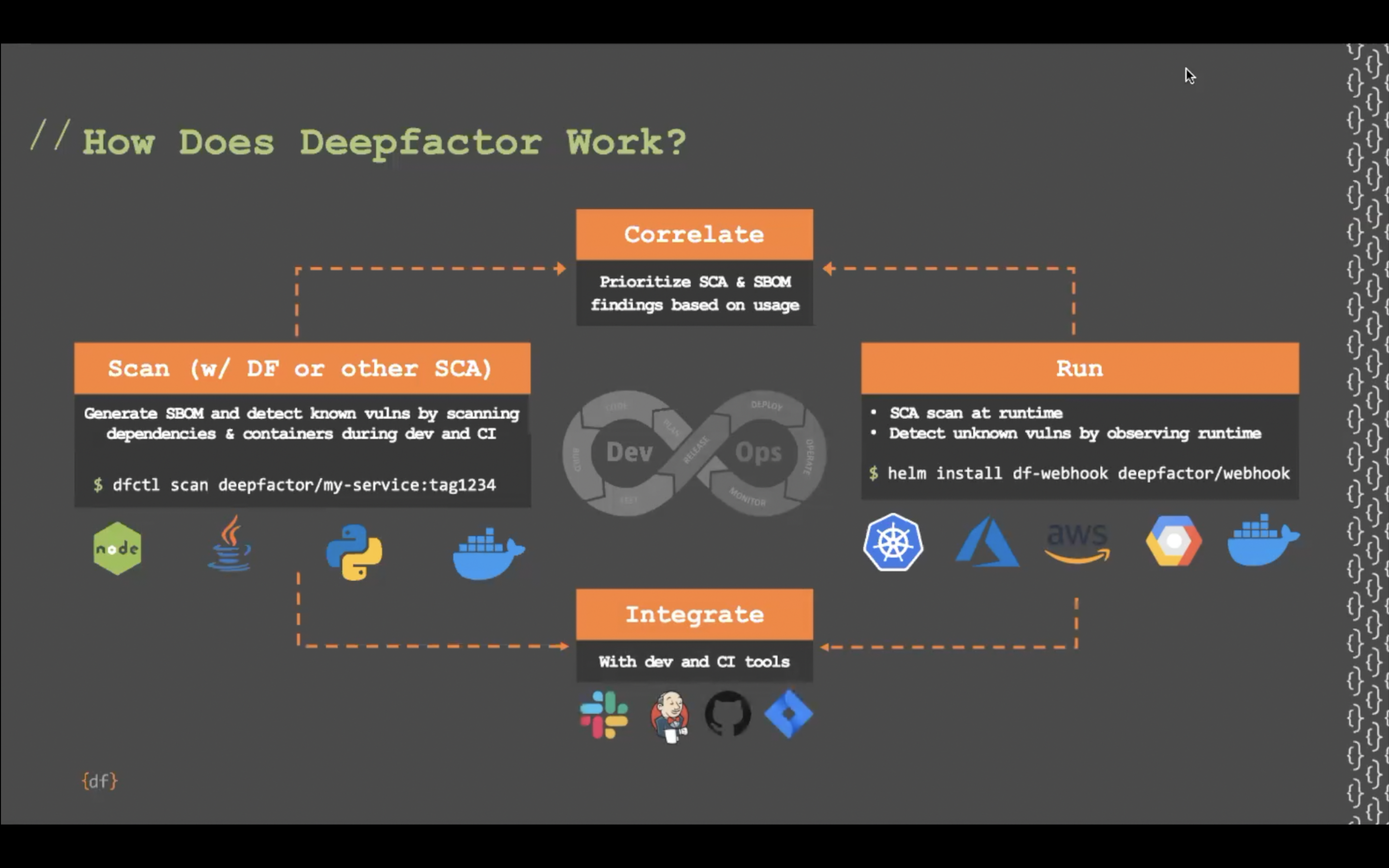
DeepFactor is a fantastic way to easily insert observability into your CI pipeline.
- Requires zero code changes to the app
- Is agnostic to the language in which the app is written
- Uses one, simple dfctl command
- Works with any workload (container/Kubernetes/Docker or even traditional apps) and any cloud
- Has low—single-digit—performance overhead
- And plugs into any CI platform.
observes BILLIONS of live application telemetry events in every thread/process/container to identify and triage security and compliance risks across various layers of the application stack—system calls, library calls, and network, web, API, and configuration layers. It’s easy to insert into your testing and staging environments, and you could also choose to turn it on in production to complement the insights you’re receiving from your production monitoring tools.
Designed for today’s modern apps, DeepFactor is the industry’s first Continuous Observability platform to fill the void between static code scanners (SAST) and dependency scanners (SCA or container image scanning) on the left and operator tools (Container/Kubernetes/Docker security, security monitoring, and vulnerability scanning tools) on the right.
Engineering teams will see many benefits from DeepFactor and are finally able to provide secure code at speed without being crushed by alert fatigue and context switching. Our technology not only detects RUNTIME security risks not detected by static code scanners but also helps prioritize dependency scan results based on which vulnerable functions were actually used by the app. The output is low volume, high-fidelity alerts.
Engineering leadership can accelerate productivity and decrease mean-time-to-remediate (MTTR) security and compliance risks pre-production as their teams ship secure releases on schedule using a purpose-built continuous observability tool.
The Application Security team can establish guardrails, prioritize alerts, and empower engineering teams to abate security risks before production using automated, continuous visibility into the actual RUNTIME behavior of every build.
If you want your engineering team or AppSec Team or both to move from good to great, you must make Continuous Observability part of your CI/CD pipeline.
———-
1Yes, there are existing DevSecOps tools that look at the “running car”—such as DAST & IAST—but they were designed over a decade ago….which means they’re not really built for CI pipelines and they’re pre-Kubernetes, pre-developers-need-security-first-mindset, and before the shift-left movement that empowers developers to secure in the beginning, at the source.
At DeepFactor, we think like developers because we are developers. The way we approach actionability is different from other tools. I hope you’ll give our continuous observability platform a try!
DeepFactor’s deep insights cover Bill of Materials, system call risks, behavior risks, data risks, vulnerable dependency usage, OWASP risks, and more. No code change. One command. Language agnostic. Works with both Kubernetes, Docker & non-containerized workloads. Visit our product page to learn more. With DeepFactor, ship secure apps at speed with confidence. Click here to start using DeepFactor for FREE!