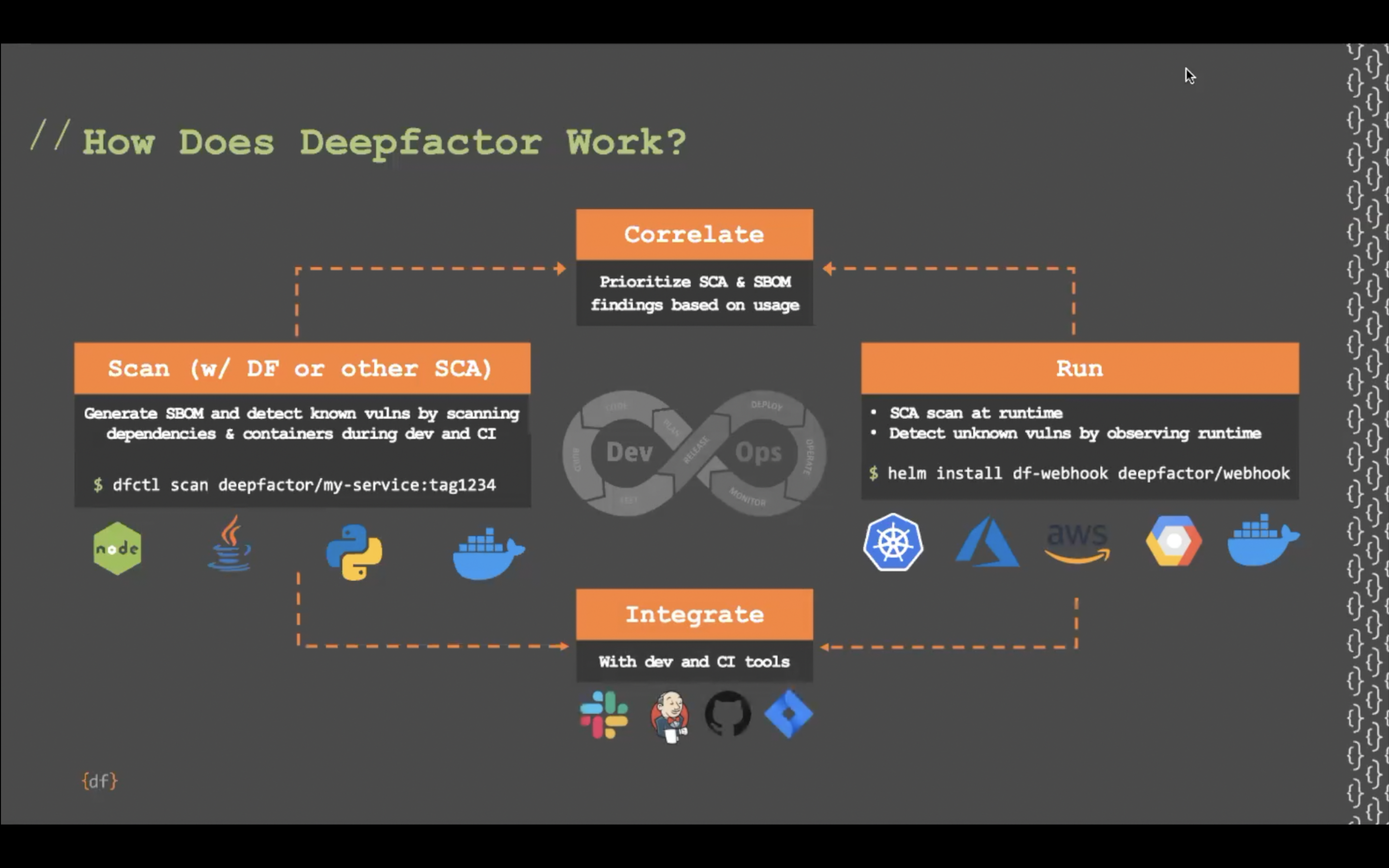

Transcript:
One of the biggest complaints with the first generation of software composition analysis and container scanning tools is that they generate too much noise. Fortunately, there are ways to cut down this noise by employing a prioritization framework.
SCA 2.0, as we fondly call it, employs a new technique called runtime software composition analysis that helps you make sense of this framework and implement prioritization into your software composition analysis and container scan output. There are six parameters that are involved that one could think about to reduce the noise that SCA container scans generate. First one is reachability. The ability to analyze an application as the application is running or by analyzing call graphs within the code of the application to determine whether certain classes or offending functions are actually reachable by the application is one of the important parameters introducing the noise.
The second parameter is runtime usage. Yes, you may have a bunch of these vulnerable components in your application, but is your application actually using them? By that I mean, is it actually loading it into memory and is it loading the specific classes that could be potentially having that vulnerability or CVE? Analyzing true runtime usage of the application is a fantastic and highly effective way to reduce the amount of noise and prioritize the things that matter to your developers. The third factor is applicability. For example, if your developer is building an application and that has a bunch of CVEs, let’s say Java as an example, if the CVE is applicable to JDK framework 7.0, then it may not be applicable to a 8.5, for example. Then understanding whether the CVE is applicable to the framework that your applications actually using can help you reduce some of the noise as well.
The fourth parameter is exploitability. There’s a bunch of exploits that are available in the field that script kiddies or attackers can leverage to instantly exploit your application. So knowing whether there is an active exploit available or if there’s a breach that has already happened using those exploits can help reduce and prioritize the things that matter most, especially when you have a time crunch and you want to truly reduce the number of things that you want to show to your developers or have them fix in a short span of time. The fifth parameter is topology. Understanding whether you have a service that is exposed to the internet can help you reduce some of the noise as well, because certain CVEs may not be applicable if your application is not exposed to the internet. And the last one is severity.
Severity comes in two different flavors. One is CVSS scores, the other one is vendor assigned severity. Sometimes it may not accurately match the CVSS score. For example, we do see out there that some CVEs have a CVSS score of greater than nine, however, it may still be marked as a high, not a critical.
Watching for these things can also help you reduce the noise. So ideally, as an AppSec team, you should be pointing your developers to the vulnerabilities or the list of components that are at the intersection of these six parameters, and that will help the AppSec teams efficiently prioritize the list of things that matter to the dev teams. What this results in is , number one, the dev teams start taking AppSec programs more seriously because they’re given a meaningful number of short list of things to fix. It helps them prioritize, it helps them focus their time on security things and then go back to the standard feature development activities that they may be engaged in.
Number two, it also helps you understand that there may be a bunch of vulnerable components that are sitting in your container images or your applications that may actually not be used. And if so, this gives a framework to remove them from your containers or switch to an alternative base image that may not have those components and so on and so forth. Lastly, employing this framework can help be better prepared when a new zero-day vulnerability comes along. For example, when the open redirect vulnerability came about in the Thanksgiving timeframe of 2022, there were teams that were frantically looking to go fix every single instance of that vulnerable openness to sell in their container images. While that certainly ruined many peoples’ Thanksgiving vacation plans, it also makes the AppSec team come across as less mature if there’s a lot of these last-minute panics, especially around a holiday season.
Instead, if the AppSec team, now armed with this information of whether there is a component that is used or not, goes to the dev team and only tells them to fix the things that are truly in use and loaded into memory, and then go back and take the Thanksgiving break and then come back and fix the remaining things, that makes for a much more mature way of handling zero-day vulnerabilities and makes for a more harmonious kind of dev and AppSec relationship as well. So instead of looking at, “Here’s the total, here’s the vulnerable, here’s the severe,” start employing this other metric of used which conveys both usage reachability and topology.
If those factors are taken into account, then you can reduce the amount of noise that you’re actually throwing at your developers resulting in, like I said, prioritization of used vulnerable components, deprioritization of or possibly consideration of removal for components that are not used. And lastly, being better equipped, better prepared when a new zero-day vulnerability comes up.